EvoVid:
Temporal-Centric Self-Evolution for Video Large Language Models
Abstract
Recent Video Large Language Models (Video-LLMs) have demonstrated strong capabilities in video reasoning through reinforcement learning (RL). However, existing RL pipelines rely heavily on human-annotated tasks and solutions, making them costly to scale and fundamentally constrained by human expertise. Self-evolving frameworks have recently emerged as a promising alternative through autonomous Questioner–Solver self-play. Unfortunately, these approaches are primarily designed for static modalities such as text and images, fundamentally failing to capture the temporal dynamics that are central to video reasoning. In this work, we propose EvoVid, a temporal-centric self-evolving framework that enables Video-LLMs to improve directly from raw, unannotated videos. Specifically, we introduce two complementary temporal-centric rewards: a temporal-aware Questioner reward that encourages temporally dependent question generation through temporal perturbation sensitivity, and a temporal-grounded Solver reward that provides automatic temporal supervision via inherent video segment localization. Extensive experiments across four base models and six benchmarks demonstrate consistent improvements over both base models and existing self-evolving baselines, achieving competitive performance with supervised methods. These results highlight temporal-centric self-evolution as an effective and scalable paradigm for video understanding and reasoning.
Contributions
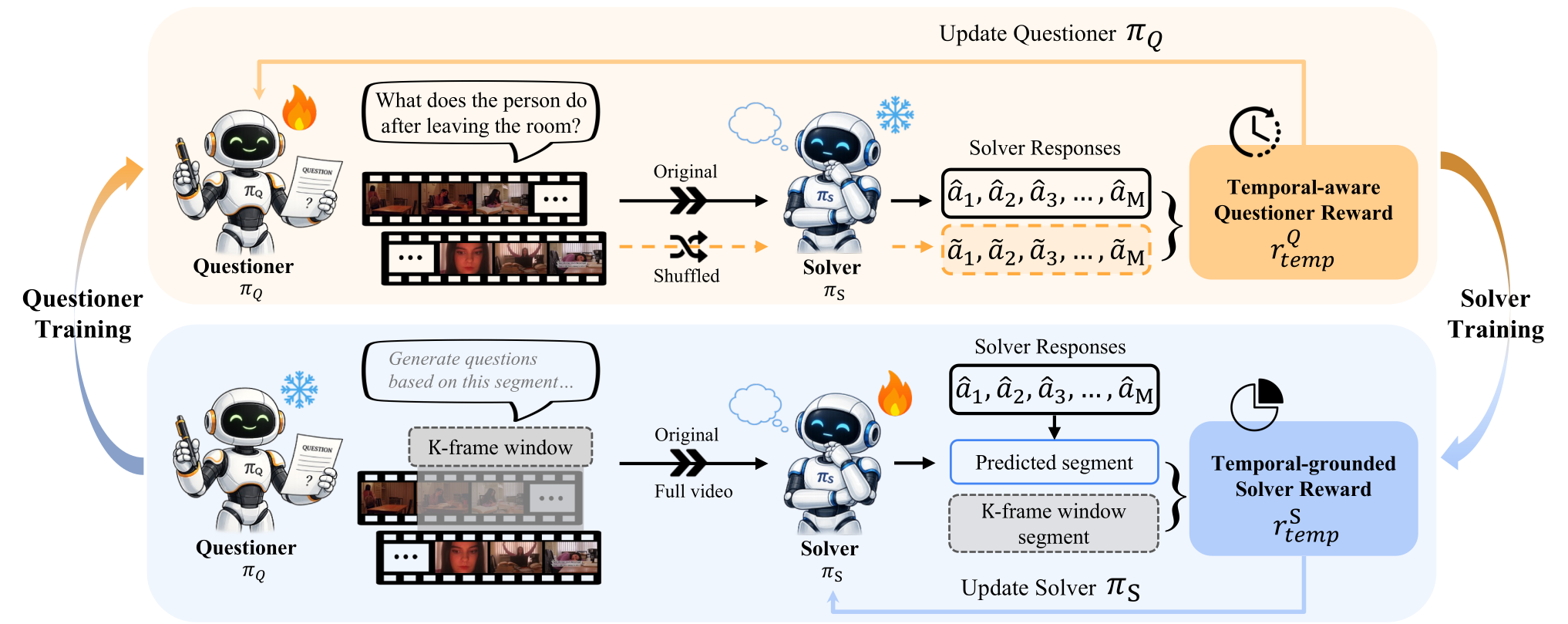
- First self-evolving framework for Video-LLMs. EvoVid improves video understanding and reasoning directly from raw, unannotated videos, without relying on any human supervision.
- Two temporal-centric verifiable rewards. A temporal-aware Questioner reward that preserves temporal perturbation sensitivity, and a temporal-grounded Solver reward that leverages inherent temporal segment supervision.
- Extensive validation. Across four MLLMs and six video understanding and reasoning benchmarks, EvoVid delivers consistent gains, validating the effectiveness of video-based self-evolution.
Main Results
Across four MLLMs (Qwen2.5-VL-3B/7B and Qwen3-VL-4B/8B) and six video reasoning and general benchmarks, three iterations of EvoVid co-evolution yield consistent improvements over each base model—despite using no human-curated questions or annotations. The model progressively improves through a fully autonomous learning process, with the largest gains on temporally challenging benchmarks (e.g., +19.3% TempCompass on Qwen2.5-VL-3B).
Performance on video reasoning and general benchmarks across four MLLMs. For each base model we compare the untrained Base Model, the frozen-Questioner baseline, and three iterations of EvoVid co-evolution. Bold marks the best result per model; blue superscripts on the Iter-3 row report the absolute improvement over the corresponding base model.
| Methods | Video-Holmes | VSI-Bench | VideoMMMU | MMVU | TempCompass | VideoMME |
|---|---|---|---|---|---|---|
| Qwen2.5-VL-3B-Instruct | ||||||
| Base Model (w/o training) | 26.8 | 25.1 | 30.6 | 48.5 | 28.9 | 48.0 |
| EvoVid ( Questioner) | 27.8 | 26.3 | 35.0 | 53.3 | 34.5 | 48.3 |
| EvoVid (Iter 1) | 28.0 | 29.5 | 34.4 | 51.7 | 33.2 | 47.0 |
| EvoVid (Iter 2) | 26.9 | 28.4 | 36.9 | 53.1 | 46.3 | 48.9 |
| EvoVid (Iter 3) | 27.2+0.4 | 29.5+4.4 | 36.7+6.1 | 54.6+6.1 | 48.2+19.3 | 48.6+0.6 |
| Qwen2.5-VL-7B-Instruct | ||||||
| Base Model (w/o training) | 27.8 | 27.7 | 47.8 | 59.2 | 72.2 | 53.1 |
| EvoVid ( Questioner) | 28.4 | 29.3 | 46.6 | 60.5 | 72.5 | 51.5 |
| EvoVid (Iter 1) | 28.6 | 28.5 | 48.9 | 60.6 | 72.1 | 51.4 |
| EvoVid (Iter 2) | 29.9 | 30.9 | 48.3 | 60.5 | 73.1 | 53.8 |
| EvoVid (Iter 3) | 29.3+1.5 | 31.7+4.0 | 50.0+2.2 | 62.4+3.2 | 73.2+1.0 | 53.6+0.5 |
| Qwen3-VL-4B-Instruct | ||||||
| Base Model (w/o training) | 29.9 | 40.1 | 46.7 | 60.3 | 70.9 | 49.6 |
| EvoVid ( Questioner) | 30.7 | 40.6 | 45.1 | 61.1 | 70.6 | 49.6 |
| EvoVid (Iter 1) | 30.4 | 41.4 | 47.3 | 61.0 | 70.8 | 49.7 |
| EvoVid (Iter 2) | 29.1 | 43.1 | 47.3 | 62.4 | 70.9 | 49.7 |
| EvoVid (Iter 3) | 31.1+1.2 | 42.8+2.7 | 47.6+0.9 | 62.6+2.3 | 71.7+0.8 | 51.4+1.8 |
| Qwen3-VL-8B-Instruct | ||||||
| Base Model (w/o training) | 36.2 | 37.4 | 46.8 | 64.8 | 73.6 | 50.3 |
| EvoVid ( Questioner) | 36.3 | 35.3 | 47.8 | 63.7 | 73.4 | 50.4 |
| EvoVid (Iter 1) | 36.0 | 38.0 | 49.0 | 63.8 | 74.3 | 50.3 |
| EvoVid (Iter 2) | 35.2 | 38.3 | 48.1 | 67.0 | 73.7 | 51.4 |
| EvoVid (Iter 3) | 36.6+0.4 | 39.8+2.4 | 49.1+2.3 | 66.2+1.4 | 74.3+0.7 | 51.2+0.9 |